Cache Memories¶
约 464 个字 17 行代码 7 张图片 预计阅读时间 3 分钟 共被读过 次
15-213/14-513/15-513: Introduction to Computer Systems
10th Lecture, Sept 26, 2024
Today’s Topics 🎯¶
- Cache organization and operation
- Performance impact of caches
- Rearranging loops to improve spatial locality
- Using blocking to improve temporal locality - Case studies: Matrix multiplication optimizations
General Cache Concepts 💡¶
Cache Basics¶
- Smaller, faster, more expensive memory that stores a subset of data blocks from main memory.
- Data transferred in block-sized units.
- Memory is partitioned into blocks.

Cache Hit vs. Miss¶
- Hit: Requested data block is in the cache.
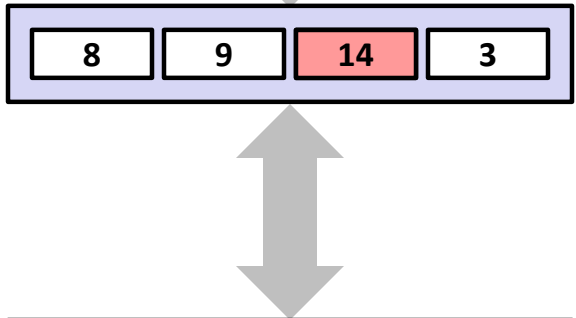
- Miss: Block not in cache. Requires fetching from memory.
- Placement policy: Determines where the block is stored.
- Replacement policy: Decides which block to evict (e.g., LRU).
Types of Cache Misses ❄️¶
- Cold (Compulsory) Miss:
- First access to a block.
- Occurs even with an infinitely large cache. - Capacity Miss:
- Cache size is smaller than the working set. - Conflict Miss:
- Too many blocks map to the same cache set.
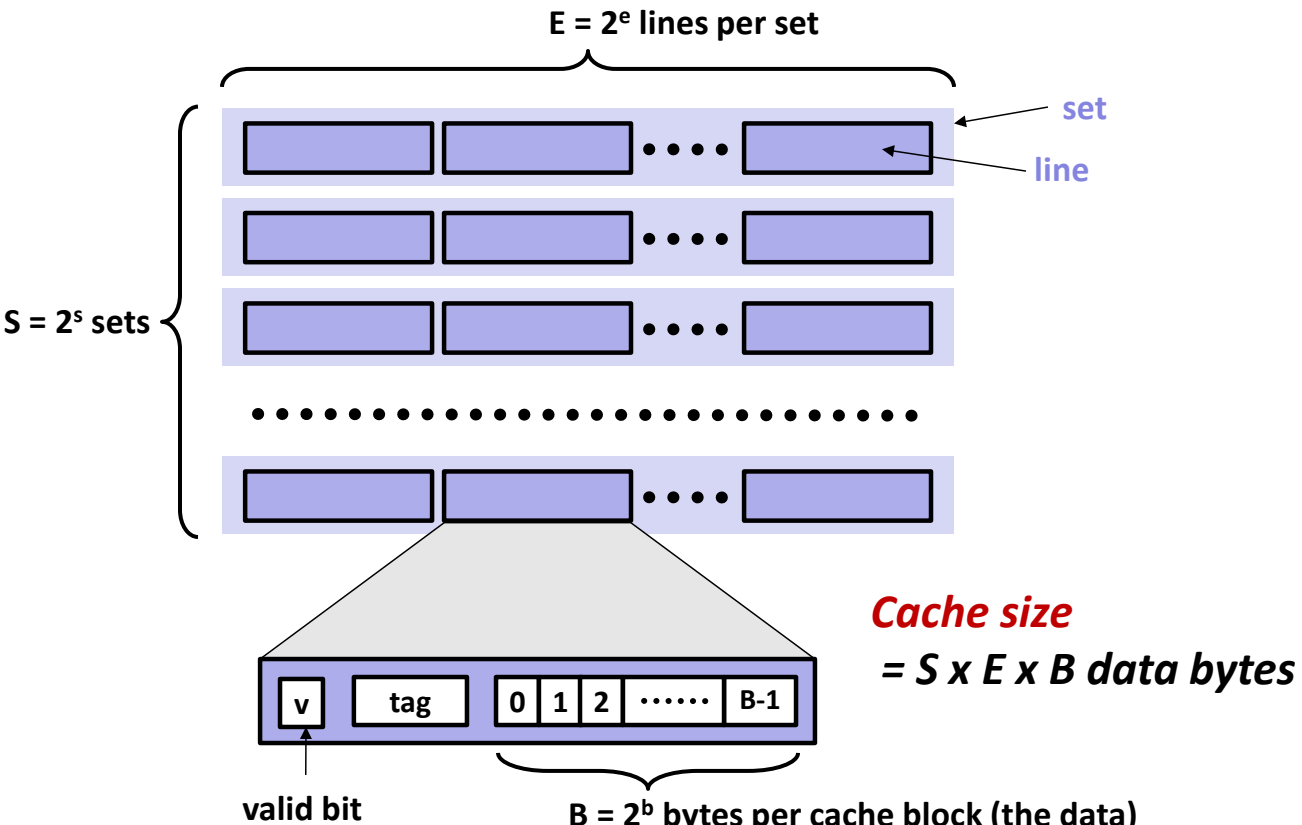
Cache Organization 🏗️¶
Parameters¶
- S: Number of sets
- E: Number of lines per set (associativity)
- B: Block size (bytes)
- Address breakdown:
- Tag: Identifies the block within a set.
- Set index: Determines the set.
- Block offset: Selects the byte within the block.
Example: Direct-Mapped Cache (E=1)¶
- 1 line per set.
- Address trace analysis:
- Block size = 8 bytes.
- 4-bit address space (M=16 bytes).
- Misses: Cold, conflict.
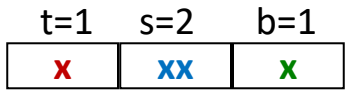
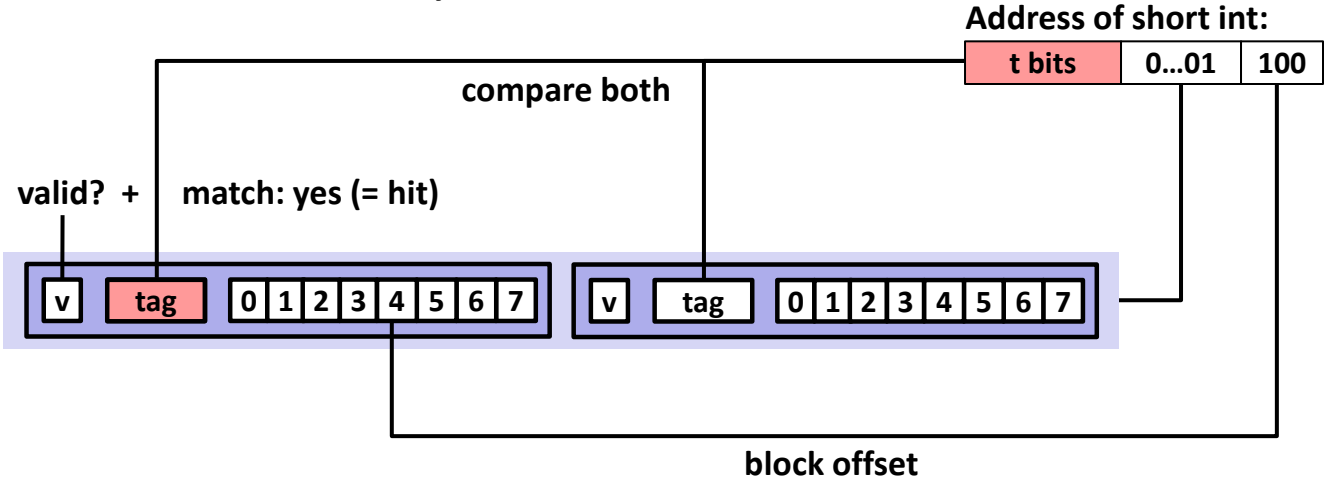
Set-Associative Cache (E=2) 🔄¶
- 2 lines per set.
- Replacement policies: LRU, random.
- Example: 4-bit addresses, S=2 sets, B=2 bytes/block.
Cache Write Policies ✍️¶
Write-Hit¶
- Write-through: Immediately write to memory.
- Write-back: Defer write until block is replaced (uses dirty bit).
Write-Miss¶
- Write-allocate: Load block into cache, then write.
- No-write-allocate: Write directly to memory.
Typical Combinations:
- Write-through + No-write-allocate
- Write-back + Write-allocate
Cache Performance Metrics 📊¶
- Miss Rate = Misses / Accesses
- L1: 3-10%, L2: <1% - Hit Time: Time to access cache (L1: ~4 cycles, L2: ~10 cycles).
- Miss Penalty: Time to fetch from memory (50-200 cycles).
Example: Hit vs. Miss Impact¶
- 97% hit rate:
Avg access time = \(1 + 0.03 \times 100 = 4\) cycles - 99% hit rate:
Avg access time = \(1 + 0.01 \times 100 = 2\) cycles
Matrix Multiplication & Cache Optimization 🧮¶
Problem Setup¶
- Multiply \(N \times N\) matrices of doubles (8 bytes each).
- Block size = 32B (holds 4 doubles).
Loop Order Analysis¶
ijk/jik Order¶
C
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
sum = 0.0;
for (k=0; k<n; k++) {
sum += a[i][k] * b[k][j];
}
c[i][j] = sum;
}
}
- Miss rates per iteration:
| A | B | C |
|---|---|---|
|0.25|1.0|0.0|
kij/ikj Order¶
C
for (k=0; k<n; k++) {
for (i=0; i<n; i++) {
r = a[i][k];
for (j=0; j<n; j++) {
c[i][j] += r * b[k][j];
}
}
}
- Miss rates per iteration:
| A | B | C |
|---|---|---|
|0.0|0.25|0.25|
Blocking Technique 🧱¶
- Split matrices into B x B blocks.
- Total misses: Reduced from \( \frac{9}{8}n^3 \) to \( \frac{n^3}{4B} \).
- Key: Maximize temporal locality by reusing blocks.
Core i7 Cache Example 🖥️¶
- L1 Data Cache:
- 32KB, 8-way set associative.
- 64B blocks.
- Address breakdown:
- Tag: 35 bits
- Set index: 6 bits
- Block offset: 6 bits
Key Takeaways 🚀¶
- Cache-friendly code:
- Focus on inner loops.
- Maximize spatial locality (stride-1 access).
- Maximize temporal locality (reuse data). - Blocking dramatically reduces cache misses by exploiting temporal locality.
- Loop reordering can significantly impact performance (e.g., ijk vs. kij).
