Lecture 05: Database Storage (Part II)¶
约 470 个字 9 行代码 5 张图片 预计阅读时间 2 分钟 共被读过 次
15-445/645 Database Systems (Spring 2025)
Carnegie Mellon University
Prof. Jignesh Patel
1. Log-Structured Storage¶
Problems with Slotted-Page Architecture¶
- Fragmentation: Deletion leaves gaps in pages, reducing space utilization.
- Useless Disk I/O: Entire block must be fetched to update a single tuple.
- Random Disk I/O: Updating multiple tuples across different pages is slow.
Solution: Log-Structured Storage (append-only model, e.g., HDFS, Google Colossus).
Log-Structured Storage Overview¶
- MemTable: In-memory structure (e.g., sorted key-value store) for fast writes.
- SSTable (Sorted String Table): Immutable on-disk files storing sorted log entries.
- Each entry contains:
- Tuple’s unique identifier
- Operation type (
PUT/DELETE) - Tuple contents (for
PUT)
Workflow:
1. Writes are appended to the MemTable.
2. When MemTable fills, it’s flushed to disk as an SSTable (sorted by key).
3. Reads check MemTable first, then SSTables from newest to oldest.

Compaction¶
- Purpose: Merge SSTables to reduce redundancy and improve read performance.
- Methods:
- Level Compaction: Merge smaller SSTables into larger ones (hierarchical tiers).
- Universal Compaction: Merge any SSTables regardless of size.
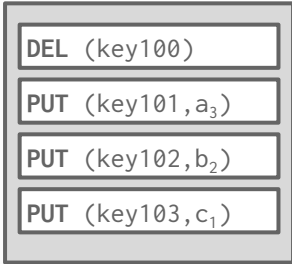
Example:
- Input SSTables:
- PUT(key101,a1), PUT(key102,b1), DEL(key103), PUT(key104,d2)
- After Compaction: Only keep the latest value for each key.
Tradeoffs¶
✅ Pros:
- Fast sequential writes (ideal for append-only storage).
- Reduced random I/O.
❌ Cons:
- Slow reads (may require scanning multiple SSTables).
- Write amplification (multiple physical writes per logical write).
- Compaction is resource-intensive.
2. Index-Organized Storage¶
- Key Idea: Store table tuples directly within an index structure (e.g., B+Tree).
- Page Layout: Similar to slotted pages, but tuples are sorted by key.
Comparison:
- B+Tree: Pay maintenance costs upfront (splits/merges).
- LSM-Tree: Pay costs during compaction.

3. Data Representation¶
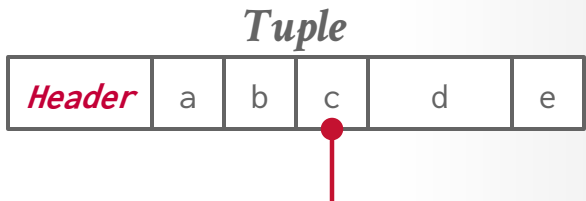
Tuple Structure¶
- Header: Metadata (e.g., null bitmap, transaction visibility).
- Data: Byte array interpreted via schema.
Word Alignment:
- Ensure attributes align with CPU word boundaries (4/8 bytes).
- Methods:
- Padding: Add empty bits after attributes.
- Reordering: Rearrange attributes physically.
Example:
CREATE TABLE foo (
id INT PRIMARY KEY, -- 32 bits
cdate TIMESTAMP, -- 64 bits
color CHAR(2), -- 16 bits
zipcode INT -- 32 bits
);
Reordered Layout:
id (32) → zipcode (32) → color (16 + 16 padding) → cdate (64) 
Data Types¶
- Integers: Fixed-length (e.g.,
INT,BIGINT). - Variable-Precision Numbers: IEEE-754 floats (fast but inexact).
- Fixed-Precision Numbers: Exact decimal/NUMERIC (stored as variable-length binary).
- Variable-Length Data:
- Header + data (e.g.,VARCHAR,BLOB).
- Overflow pages for large values. - Dates/Times: Stored as microseconds since Unix epoch.
NULL Representation:
- Null Bitmap: Centralized header indicating null attributes.
- Special Values: e.g., INT32_MIN for NULL.
4. System Catalogs¶
- Metadata: Tables, columns, indexes, users, permissions, statistics.
- Storage: Catalog tables within the DBMS itself.
Querying Catalogs:
Schema Changes:
- Add Column: Copy tuples (NSM) or create new segment (DSM).
- Drop Column: Mark deprecated or free space.
5. Large Values & External Storage¶
- Overflow Pages: Used when tuple size exceeds page limit (e.g., PostgreSQL TOAST).
- External Files:
- Stored as BLOBs (e.g., Oracle BFILE).
- Drawbacks: No durability/transaction guarantees.
Conclusion¶
- Log-Structured Storage: Optimized for write-heavy workloads.
- Index-Organized Storage: Sorted storage with upfront maintenance.
- Data Alignment: Critical for CPU efficiency.
- System Catalogs: Centralized metadata management.
🚀 Key Takeaway: Storage architecture choices depend on workload (read vs. write-heavy) and performance tradeoffs.