Lecture 5: Performance Optimization Part 1 - Work Distribution and Scheduling¶
约 361 个字 32 行代码 10 张图片 预计阅读时间 2 分钟 共被读过 次
CMU 15-418/618, Fall 2018
Key Goals of Parallel Program Optimization 🎯¶
- Balance workload across execution resources.
- Reduce communication to avoid stalls.
- Minimize overhead from parallelism management.
TIP #1: Always start with the simplest solution, then measure performance.
"My solution scales" = Your code scales as needed for your target hardware.
Balancing the Workload ⚖️¶
Ideal Scenario: All processors compute simultaneously and finish at the same time.
Amdahl’s Law Impact¶
- Example: If P4 does 20% more work → P4 takes 20% longer → 20% of runtime becomes serial execution.
- Serialized section (S) = 5% of total work → Limits maximum speedup.

Static Assignment 🔧¶
Definition: Pre-determine work-to-thread mapping (may depend on runtime parameters).
Example: Grid Solver¶
- Assign equal grid cells to each thread.
- Strategies:
- Blocked: Contiguous chunks.
- Interleaved: Cyclic distribution.
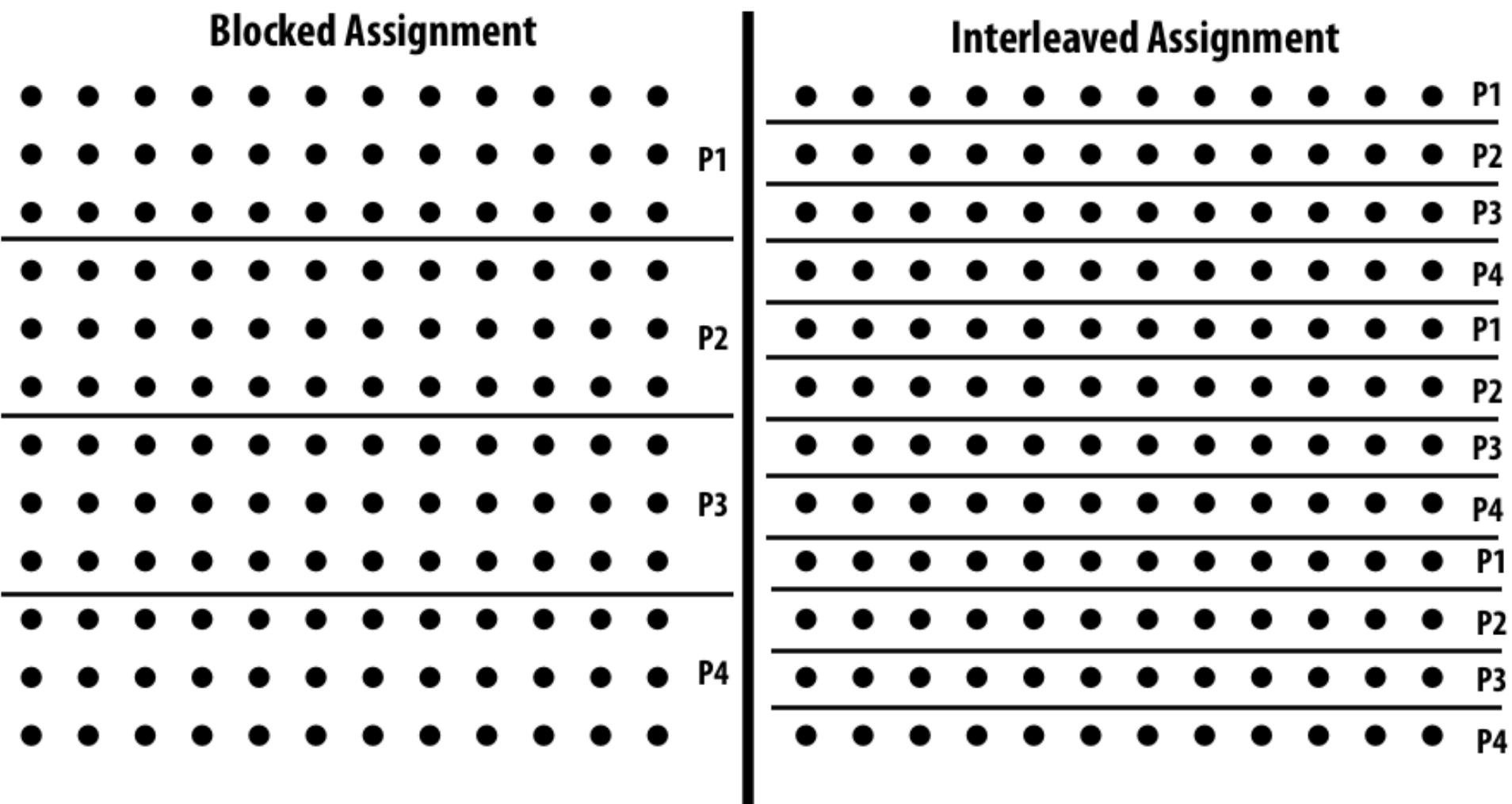
When to Use Static Assignment?¶
- Predictable work cost (e.g., uniform task durations).
- Known statistics (e.g., average execution time).
Example: 12 tasks with equal cost → Assign 3 tasks to each of 4 processors.
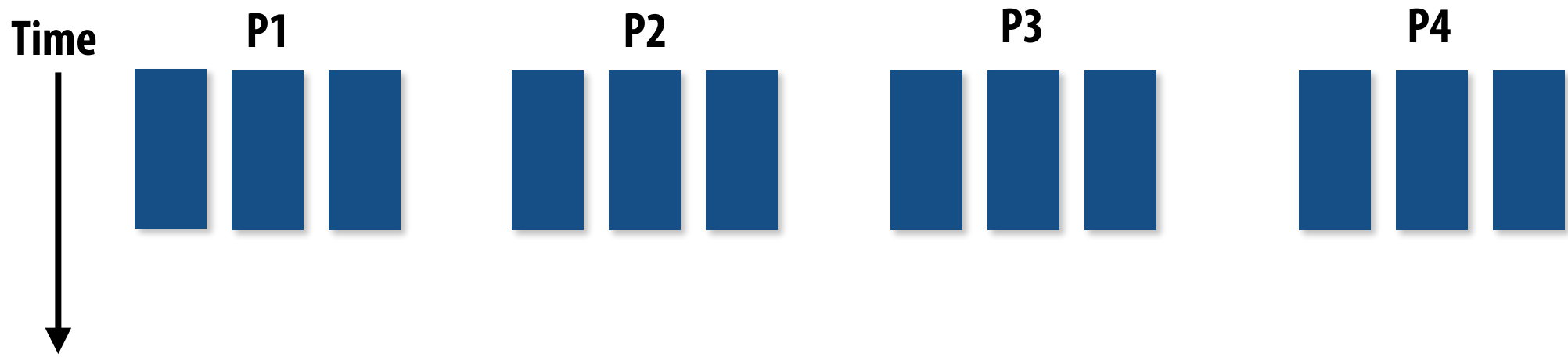
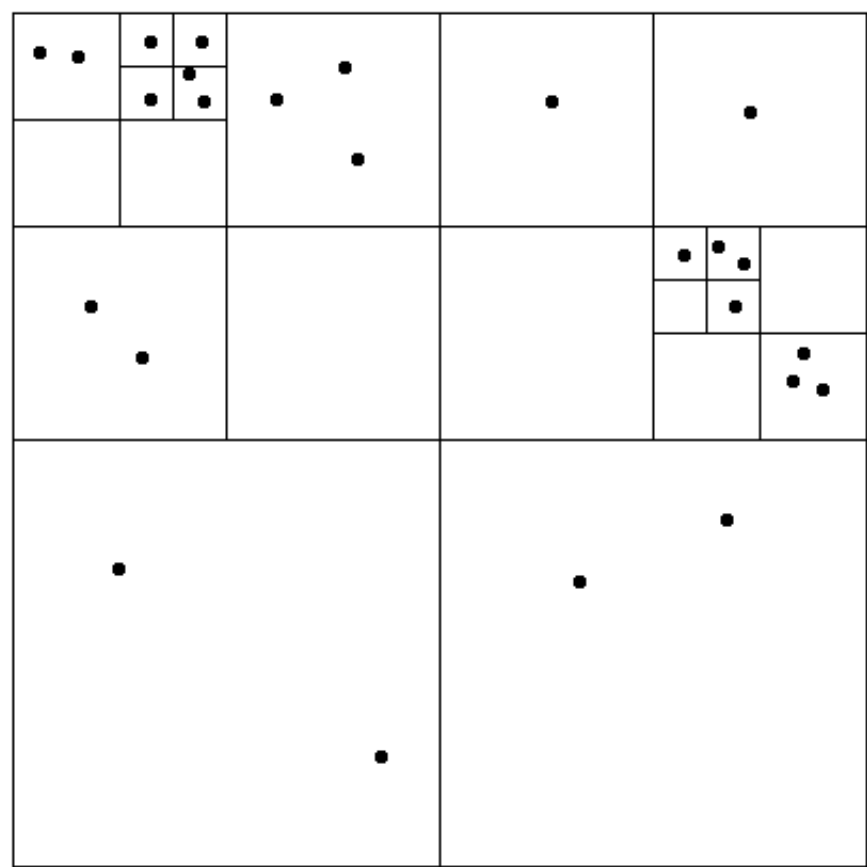
Semi-Static Assignment 🔄¶
- Periodic profiling to adjust assignments.
- Example: Particle simulation redistributes particles as they move slowly.
Dynamic Assignment 🚀¶
Use Case: Unpredictable task execution time/number.
Shared Counter Example (Prime Testing)¶
int N = 1024;
int* x = new int[N];
bool* is_prime = new bool[N];
LOCK counter_lock;
int counter = 0;
while (1) {
int i;
lock(counter_lock);
i = counter++;
unlock(counter_lock);
if (i >= N) break;
is_prime[i] = test_primality(x[i]);
}
Problem: High synchronization overhead due to frequent lock contention.
Task Granularity Adjustment 🧩¶
Coarse Granularity: Reduce synchronization by grouping tasks.
const int GRANULARITY = 10;
...
counter += GRANULARITY;
for (int j = i; j < end; j++) {
is_prime[j] = test_primality(x[j]);
}
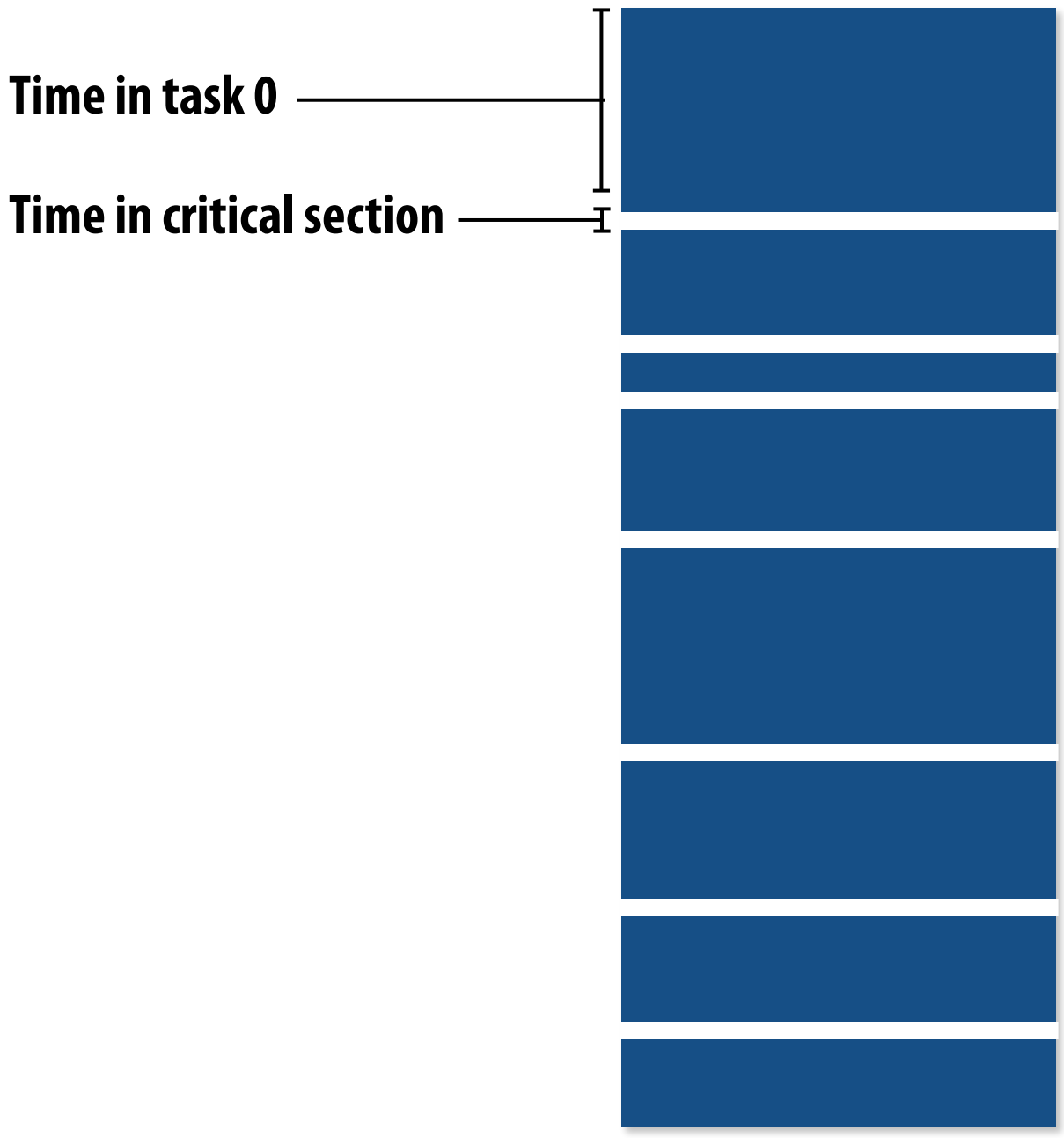
Trade-off:
- Small tasks → Better load balance.
- Large tasks → Lower overhead.
Smarter Task Scheduling 🧠¶
Problem: Load Imbalance¶
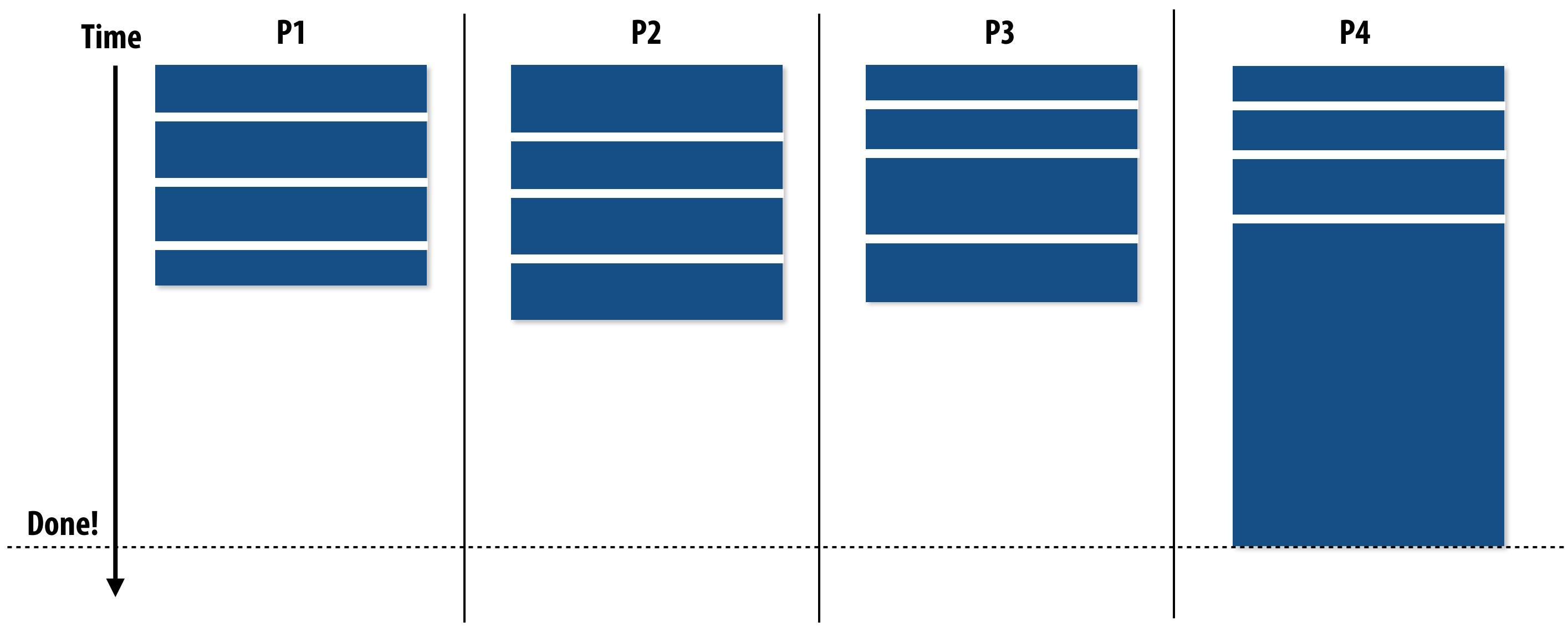
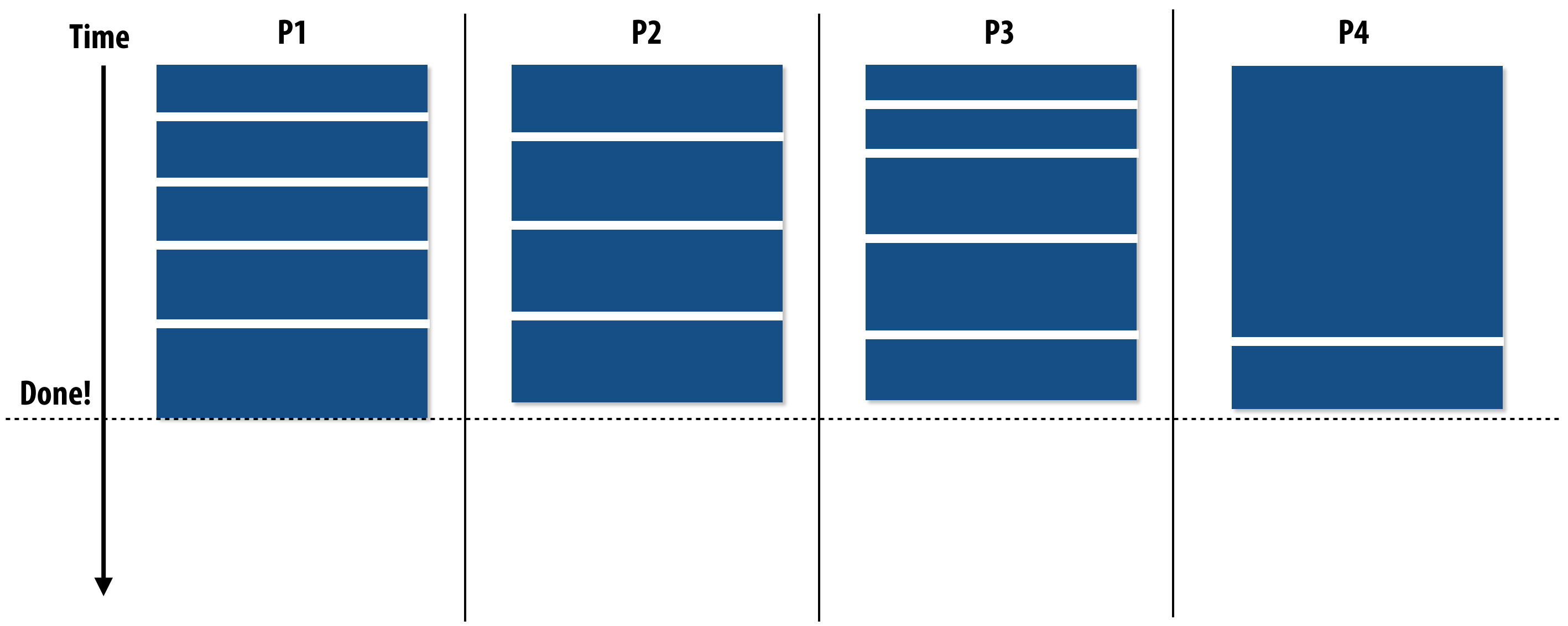
Solutions:
1. Split long tasks into smaller subtasks.
2. Schedule long tasks first to minimize "slop".
Distributed Work Queues 🗃️¶
Design:
- Each thread has its own work queue.
- Work stealing when local queue is empty.
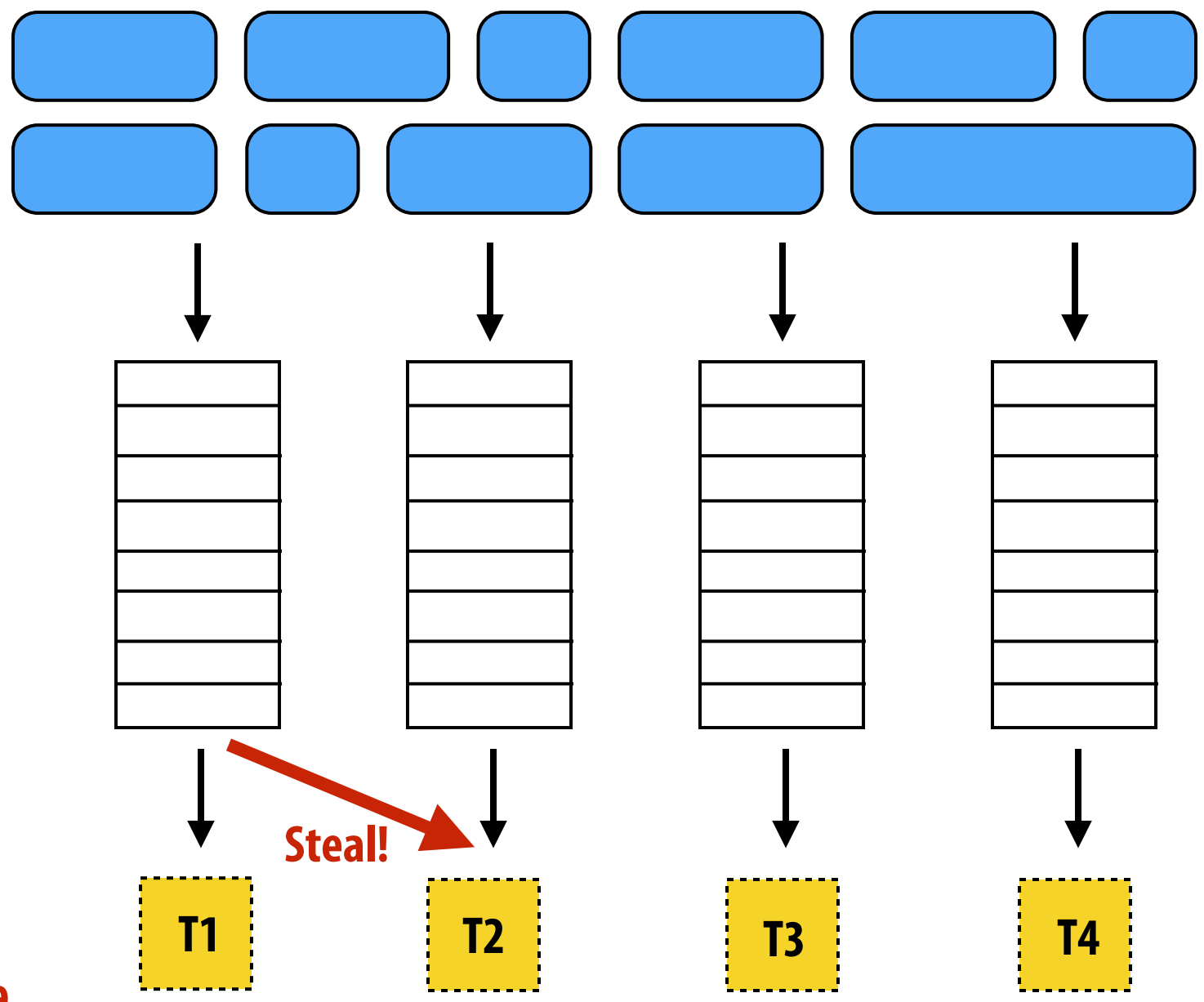
Advantages:
- Reduced synchronization.
- Improved locality (producer-consumer pattern).
Fork-Join Parallelism with Cilk Plus 🛠️¶
Key Constructs:¶
cilk_spawn: Fork a task.cilk_sync: Join all spawned tasks.
Example: Parallel QuickSort
void quick_sort(int* begin, int* end) {
if (begin >= end - PARALLEL_CUTOFF) std::sort(begin, end);
else {
int* middle = partition(begin, end);
cilk_spawn quick_sort(begin, middle);
quick_sort(middle + 1, end);
}
}
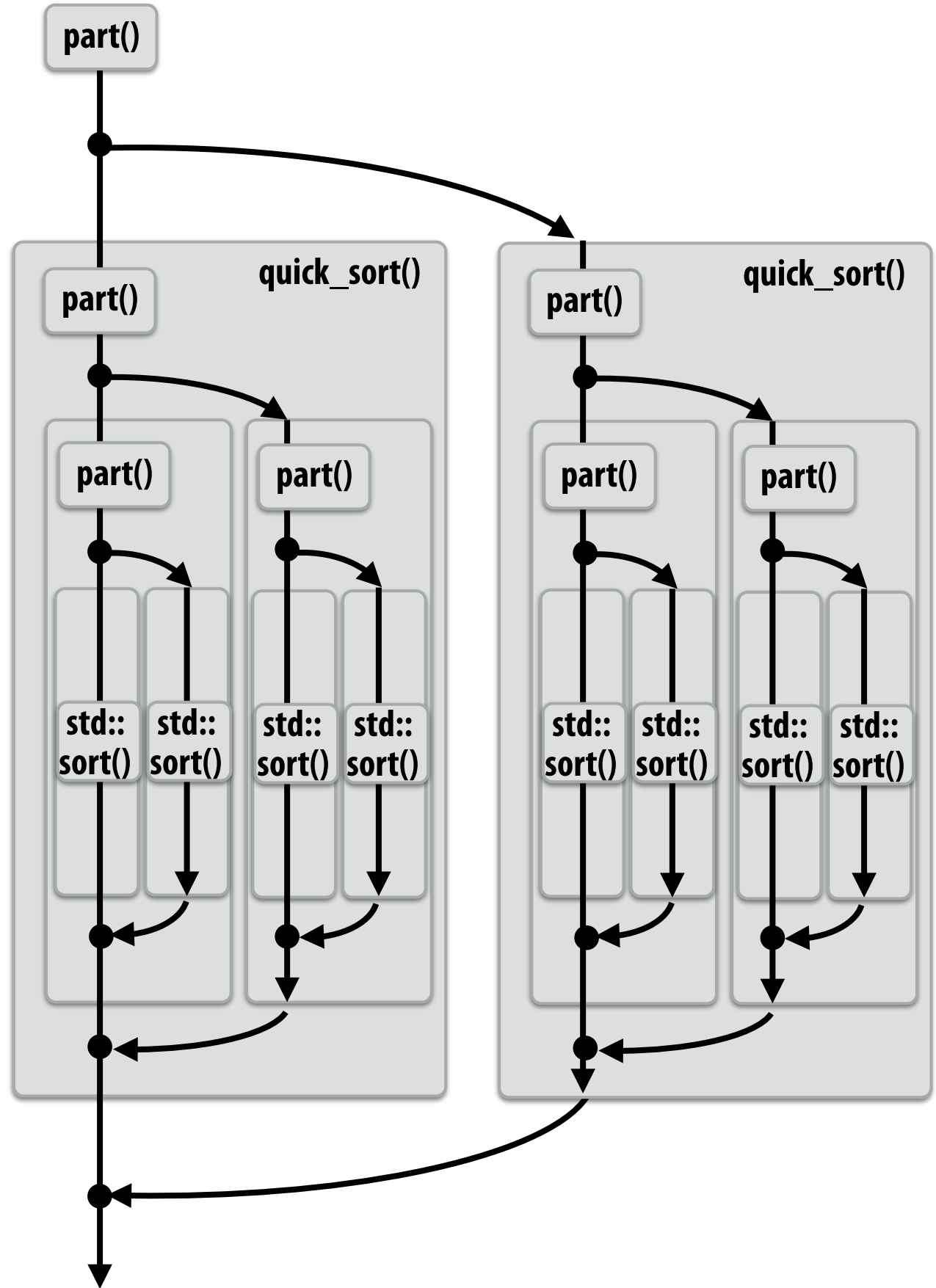
Work Stealing Scheduler 🕵️¶
- Continuation Stealing: Run child task first, leave continuation for stealing.
- Greedy Policy: Idle threads steal work immediately.
Example: Loop with cilk_spawn
Summary 📝¶
- Load Balance: Critical for maximizing resource utilization.
- Assignment Strategies:
- Static: Predictable workloads.
- Dynamic: Unpredictable workloads (use work queues). - Fork-Join: Natural for divide-and-conquer (Cilk Plus uses work stealing).
- Granularity: Balance task size to minimize overhead and ensure parallelism.
Key Insight: Use workload knowledge to choose the right strategy! 🚀