Lecture 3: Parallel Programming Abstractions & Implementations¶
约 440 个字 45 行代码 11 张图片 预计阅读时间 3 分钟 共被读过 次
CMU 15-418/15-618, Fall 2018
📌 Theme: Abstraction vs. Implementation¶
Key Idea: Conflating abstraction with implementation causes confusion.
🖥️ Example: Programming with ISPC¶
Intel SPMD Program Compiler (ISPC)¶
- SPMD: Single Program Multiple Data.
- Goal: Compute \(\sin(x)\) using Taylor expansion:
\(\(\sin(x) = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + \dots\)\)
C++ Code (Main Program)¶
#include "sinx_ispc.h"
int N = 1024;
int terms = 5;
float* x = new float[N];
float* result = new float[N];
// Initialize x
sinx(N, terms, x, result);
ISPC Code (sinx.ispc)¶

Key Concepts:
- programCount: Number of program instances (uniform value).
- programIndex: ID of the current instance (non-uniform, "varying").
- uniform: Type modifier for variables shared across instances.
Assignment Strategies¶
-
Interleaved Assignment:
- Elements assigned to instances in a round-robin fashion.
- Efficient for contiguous memory access (uses SIMD packed loads).
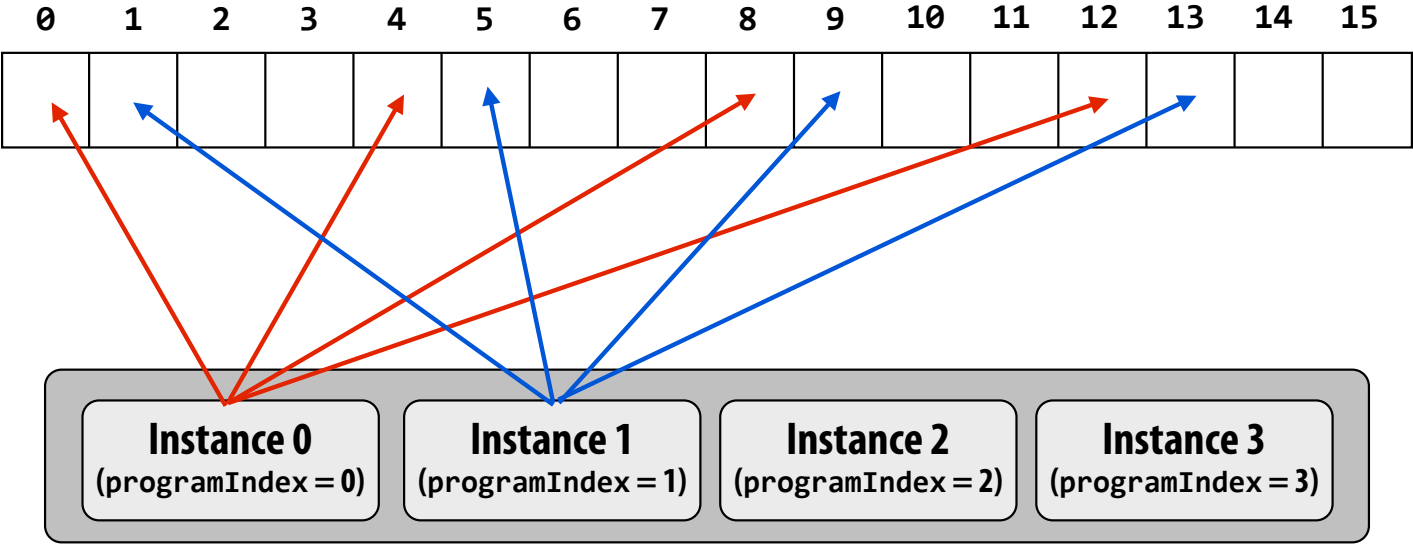
-
Blocked Assignment:
- Each instance processes a contiguous block of elements.
- Requires "gather" instructions (costlier on non-contiguous data).
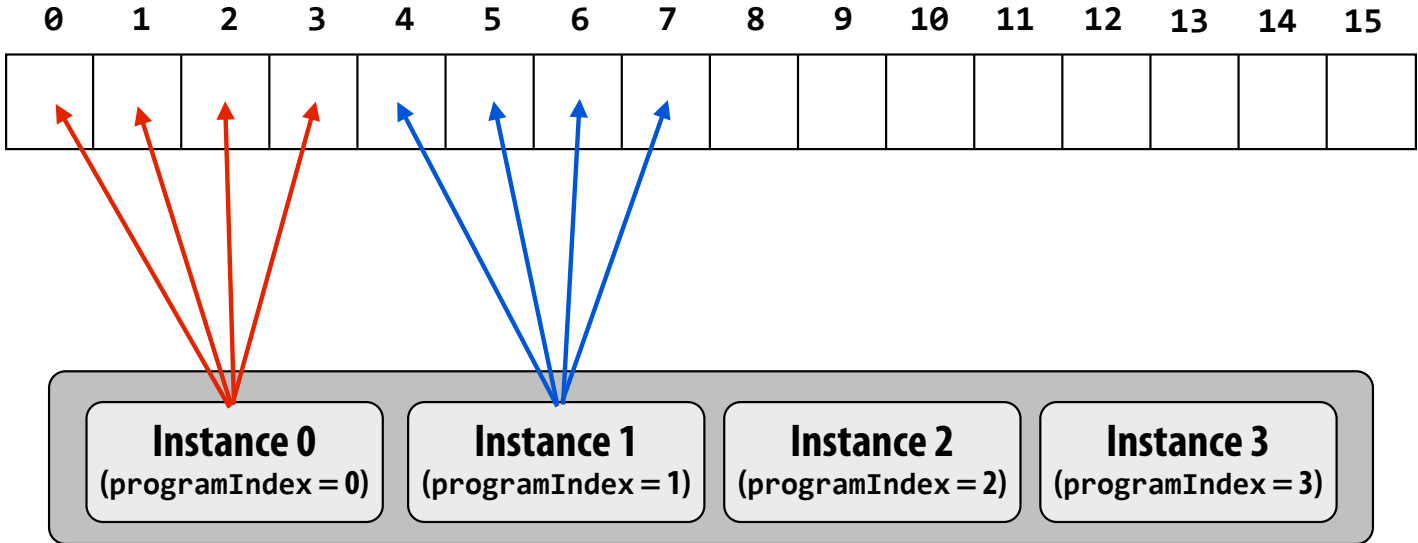
ISPC foreach Construct¶
export void absolute_value(uniform int N, uniform float* x, uniform float* y) {
foreach (i = 0 ... N) {
if (x[i] < 0) y[i] = -x[i];
else y[i] = x[i];
}
}
Behavior:
- Parallel loop iterations split across program instances.
- Static interleaved assignment by default.
📊 Three Parallel Programming Models¶
1. Shared Address Space¶
Abstraction:
- Threads communicate via shared variables (implicit) and synchronization primitives (e.g., locks).
Example:
HW Implementations:
- SMP (Symmetric Multi-Processor): Uniform memory access (UMA).
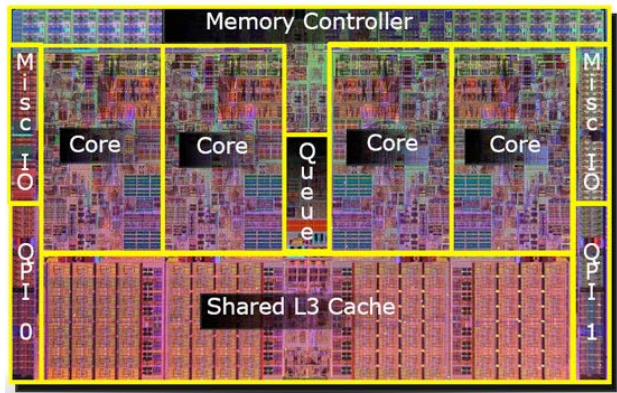
- NUMA (Non-Uniform Memory Access): Scalable but requires locality awareness.

2. Message Passing¶
Abstraction:
- Threads communicate via explicit send/receive operations.
Implementation:
- MPI (Message Passing Interface) on clusters.
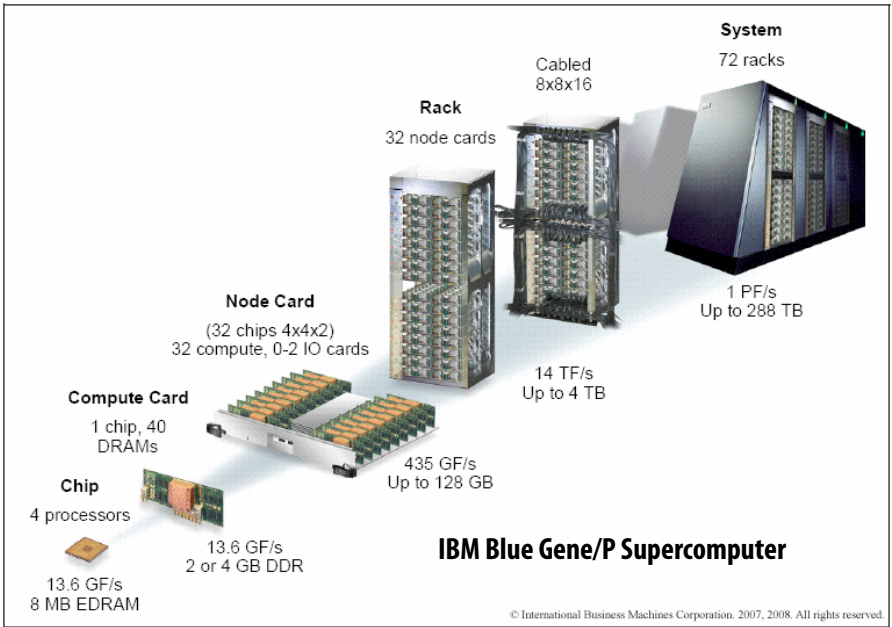
Example:
3. Data Parallel¶
Abstraction:
- Apply the same operation to all elements of a collection (e.g., map function).
ISPC Example:
export void shift_negative(uniform int N, uniform float* x, uniform float* y) {
foreach (i = 0 ... N) {
if (i >= 1 && x[i] < 0) y[i-1] = x[i];
else y[i] = x[i];
}
}
Hardware Support:
- SIMD instructions (AVX2/AVX512) for vectorization.
- Gather/Scatter operations for non-contiguous data.
🛠️ Modern Hybrid Models¶
- Shared Address Space within a multi-core node.
- Message Passing between nodes in a cluster.
Example: LANL Roadrunner (2008 World's Fastest Supercomputer).
📝 Summary¶
| Model | Communication | Pros | Cons |
|---|---|---|---|
| Shared Address Space | Implicit (loads/stores) | Natural extension of sequential | Scalability challenges (NUMA) |
| Message Passing | Explicit (send/receive) | Structured, scalable | Verbose, harder to debug |
| Data Parallel | Implicit (element-wise) | Predictable performance | Rigid structure |
Key Takeaway: Choose abstractions that align with hardware capabilities and program requirements.
💡 Self-Test: If you understand why
reduce_add()in ISPC maps to AVX intrinsics, you've mastered the gang abstraction!
C++// AVX equivalent of ISPC reduction float sumall2(int N, float* x) { __m256 partial = _mm256_broadcast_ss(0.0f); for (int i=0; i<N; i+=8) partial = _mm256_add_ps(partial, _mm256_load_ps(&x[i])); float tmp; _mm256_store_ps(tmp, partial); float sum = 0.f; for (int i=0; i<8; i++) sum += tmp[i]; return sum; }

🧩 Advanced Topics¶
ISPC Tasks¶
- Gang Abstraction: Implemented via SIMD instructions on a single core.
- Multi-Core Execution: Requires the
taskabstraction (not covered here).
Stream Programming¶
- Kernels: Side-effect-free functions applied to collections (streams).
- Optimizations: Prefetching and locality exploitation via compiler analysis.
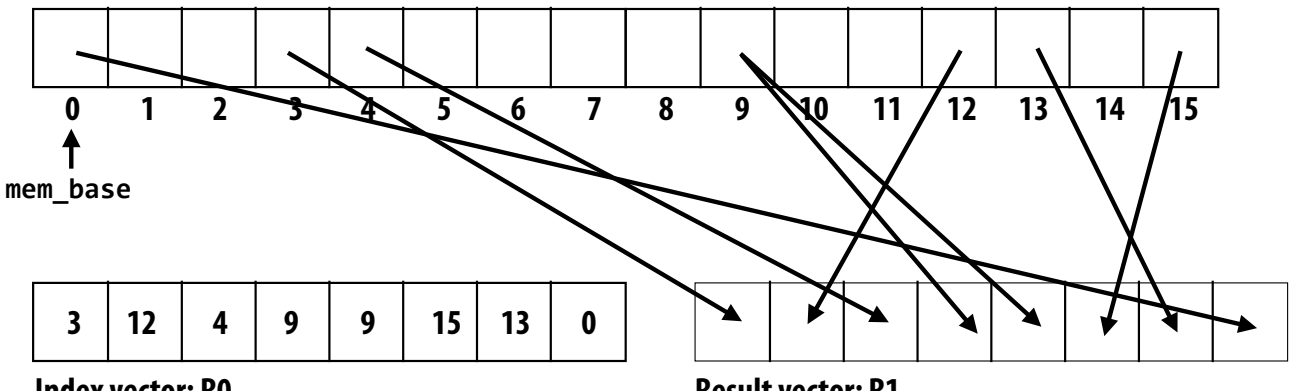
Gather/Scatter Operations¶
- Gather: Load non-contiguous data into a SIMD register.
- Scatter: Store SIMD register to non-contiguous memory locations.
🔍 Implementation Details¶
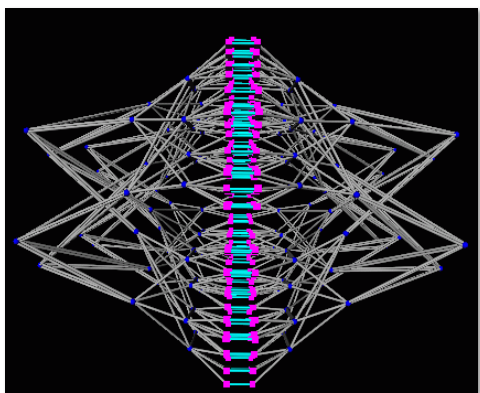
SGI Altix UV 1000¶
- 4096 cores with a fat-tree interconnect.
- Shared address space across 256 blades.
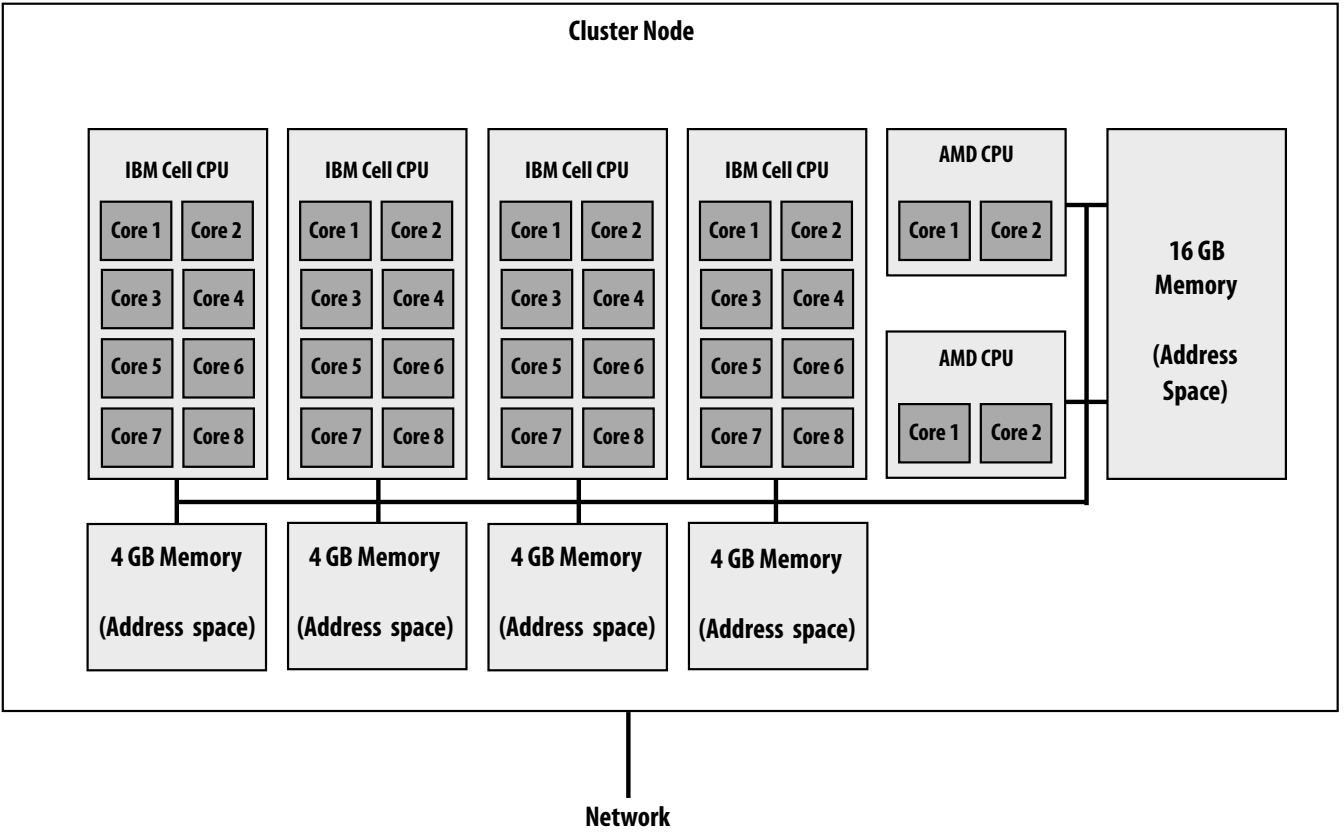
15-418/618 "Latedays" Cluster¶
- Hybrid architecture with CPUs, GPUs, and Xeon Phi coprocessors.
- Peak performance: 105 TFLOPS.
🎯 Final Notes¶
- Abstraction Distance: Balance between flexibility and predictable performance.
- Mixed Models: Use shared memory within nodes + message passing between nodes.
- Functional vs. Imperative: Data-parallel systems trade safety for familiarity.