Lecture 2: A Modern Multi-Core Processor¶
约 274 个字 49 行代码 1 张图片 预计阅读时间 2 分钟 共被读过 次
CMU 15-418/15-618, Fall 2018
Key Concepts¶
- Parallel Execution
- Multi-core processing
- SIMD (Single Instruction, Multiple Data)
- Instruction-Level Parallelism (ILP) - Memory Access Challenges
- Latency vs. Bandwidth
- Caching, Prefetching, Multi-threading
Part 1: Parallel Execution¶
Example: Computing \(\sin(x)\) Using Taylor Expansion¶
Formula:
\(\(\sin(x) = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + \ldots\)\)
Serial Code:
C
void sinx(int N, int terms, float* x, float* result) {
for (int i = 0; i < N; i++) {
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6; // 3!
int sign = -1;
for (int j = 1; j <= terms; j++) {
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
Problem: No parallelism → Slower on multi-core (0.75x speedup per core).
Parallelizing with Pthreads¶
Data-Parallel Approach:
C
void sinx(int N, int terms, float* x, float* result) {
forall(int i from 0 to N-1) { // Independent iterations
float value = x[i];
float numer = x[i] * x[i] * x[i];
int denom = 6;
int sign = -1;
for (int j = 1; j <= terms; j++) {
value += sign * numer / denom;
numer *= x[i] * x[i];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[i] = value;
}
}
Compiler Hint: Use
forall to declare independent loop iterations. Multi-Core Scaling¶
| Cores | Performance |
|---|---|
| 1 | 1x |
| 2 | 1.5x |
| 4 | 3x |
| 16 | 12x |
Example Architectures:
- Intel Core i7 (6 cores)
- NVIDIA GTX 1080 (20 SMs)
- Apple A9 (2 cores)
SIMD Vectorization¶
AVX Intrinsics Example:
C
#include <immintrin.h>
void sinx(int N, int terms, float* x, float* result) {
float three_fact = 6;
for (int i = 0; i < N; i += 8) {
__m256 origx = _mm256_load_ps(&x[i]);
__m256 value = origx;
__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));
__m256 denom = _mm256_broadcast_ss(&three_fact);
int sign = -1;
for (int j = 1; j <= terms; j++) {
__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_set1_ps(sign), numer), denom);
value = _mm256_add_ps(value, tmp);
numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));
denom = _mm256_mul_ps(denom, _mm256_broadcast_ss((2*j+2)*(2*j+3)));
sign *= -1;
}
_mm256_store_ps(&result[i], value);
}
}
Effect: 8 elements processed per instruction 🚀.
Part 2: Memory Access¶
Latency vs. Bandwidth¶
- Latency: Time to service a memory request (e.g., 100 cycles).
- Bandwidth: Data transfer rate (e.g., 20 GB/s).
Techniques to Mitigate Latency¶
- Caching: Reduce access time for frequently used data.
- Prefetching: Predict and load data before it’s needed.
- Multi-threading: Hide latency by switching threads.
Multi-Threading Trade-offs¶
| Scenario | Pros | Cons |
|---|---|---|
| Single Thread | Simple | Frequent stalls |
| 4 Hardware Threads | Better ALU utilization | Increased cache pressure |
| 16 SIMD Cores | High throughput | Requires massive parallelism |
Example: NVIDIA GTX 480 (15 cores, 32 ALUs/core, 1.3 TFLOPS).
GPU vs. CPU Memory Hierarchy¶
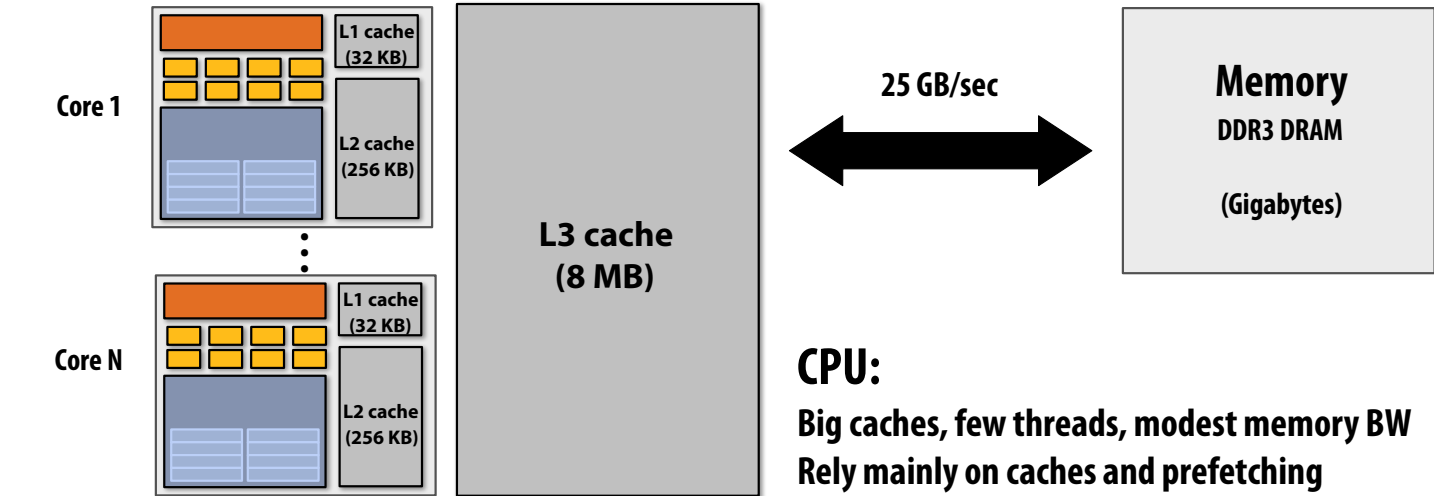
- CPU: Large caches, low latency.
- GPU: High bandwidth, optimized for throughput.
Key Takeaways¶
- Parallel Execution Forms:
- Multi-core (thread-level)
- SIMD (data-level)
- Superscalar (ILP) - Memory Challenges:
- Bandwidth-bound programs need high arithmetic intensity.
- Optimize for data reuse and locality. - Hardware Trends:
- Simpler cores + more parallelism > complex cores.
- GPUs push throughput to extremes.
🔍 Pro Tip: Use forall and vectorization to exploit parallelism!